LEARNING
Reliable AI Agents: Context, Data, and Permissions Explained
Insights from Vertesia’s Eric Barroca on the GenAI Global Podcast, hosted by MIT Prof. John R. Williams and Dr. Abel Sanchez
Introducing Vertesia’s Semantic DocPrep, a generative AI powered service designed to improve complex document processing with LLM.
We all know the power of Large Language Models (LLMs). They can summarize, analyze, and generate text with impressive fluency. But what happens when you feed them complex documents like PDFs or PowerPoints? Often, the crucial information embedded in the layout and formatting gets lost in translation. A heading loses its significance, a table becomes a jumbled mess of text, and the LLM struggles to truly understand the content.
Think about it. The way a document is structured provides vital context. A heading clearly signals a new topic, bullet points highlight key takeaways, and tables organize data into meaningful relationships. When an LLM only sees a flat text conversion, it misses these vital cues. And guess what - LLMs actually make things up! Yes, it’s true. If the LLM can’t find what it needs, it will give wrong answers, sometimes even altering accurate information. This is what the industry is calling “hallucinations” - when LLMs invent the wrong answer. When LLMs have limited context, this can also lead to:
Introducing Vertesia’s Semantic DocPrep, a generative AI powered service designed to improve complex document processing with LLMs. Vertesia intelligently transforms your documents, starting with PDFs, into structured XML files, creating a rich, semantically aware representation which offers the following benefits over other text formats:
Vertesia's Semantic DocPrep directly addresses the limitations of processing plain text, paving the way for more accurate, reliable, and insightful interaction and automation with your documents.
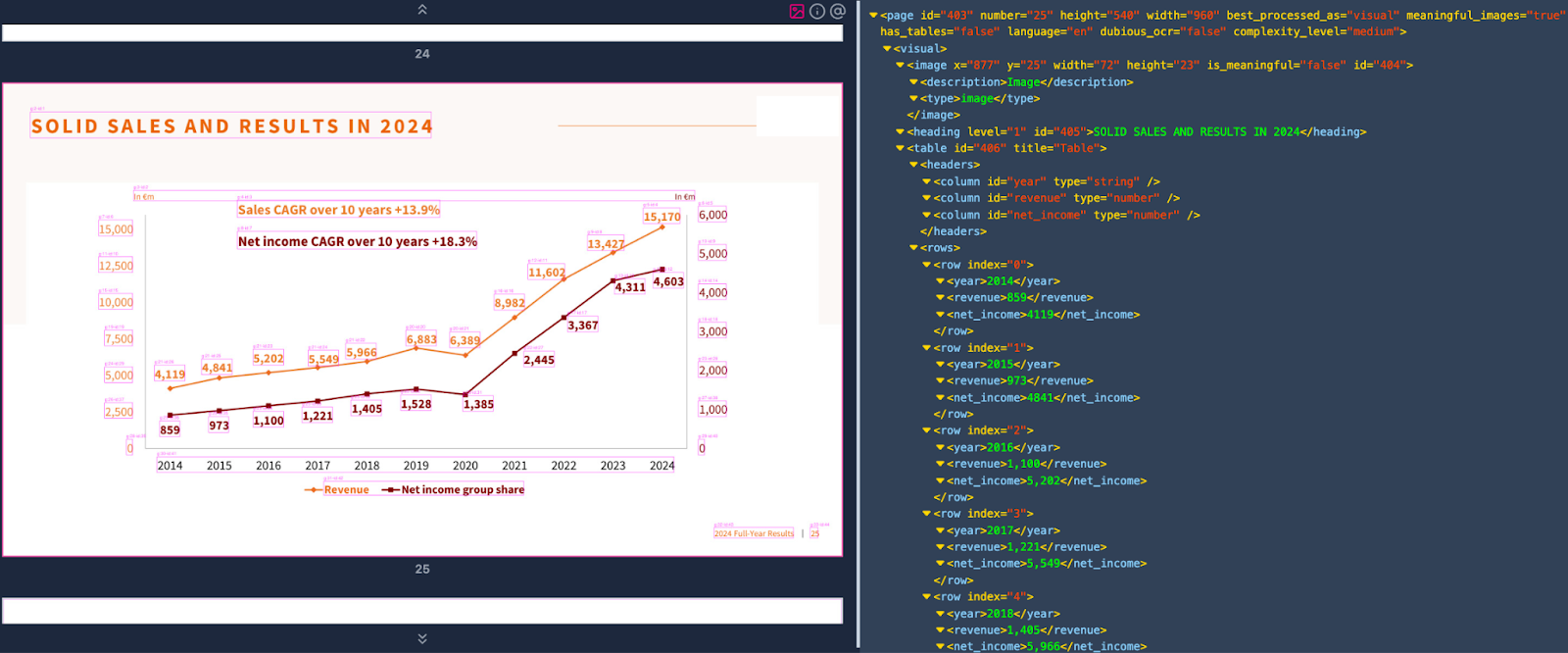
Graph converted to XML using Semantic DocPrep
**A note on semantic deconstruction
We break down the source document into understandable “chunks”, and preserve the semantic context. With other tools, the chunking strategy is naive and based on character count. This is another problem that leads to hallucinations because the chunks can lose their meaning when sentences become fragmented thoughts and related paragraphs become separated. Vertesia uses LLMs to semantically chunk content into smaller parts based on human language and the actual meaning of content, so the chunks always retain their intended meaning.
To illustrate the capabilities of Semantic DocPrep, let’s use a realistic and simple example.
As a global company, we receive a lot of commercial invoices from our global suppliers, in completely random formats which may also include other information such as a packaging list. For tax and tariffs purposes, we need to accurately extract all the line items in a consistent format.
We tried the simple approach of feeding an LLM model with the plain OCR text of our invoices, but the accuracy is nowhere near where it needs to be able to confidently automate the process, and only gets worse as the number of line items increases.
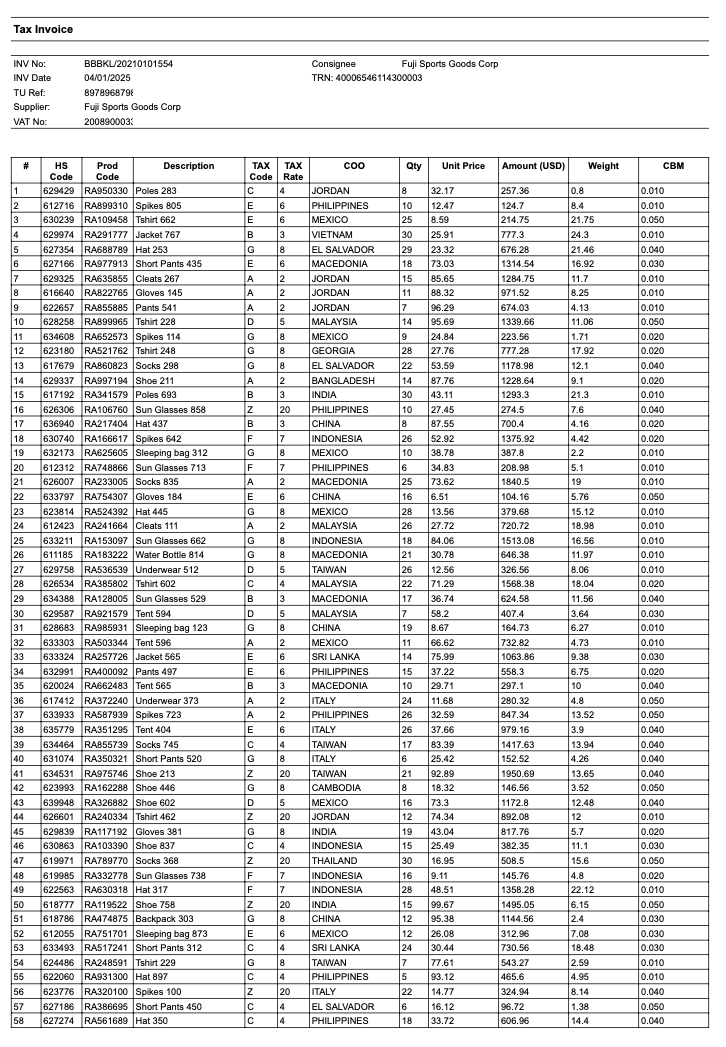
Example of the first page of an invoice
Using Vertesia’s Semantic DocPrep, the first is to upload the file and trigger a transformation to XML
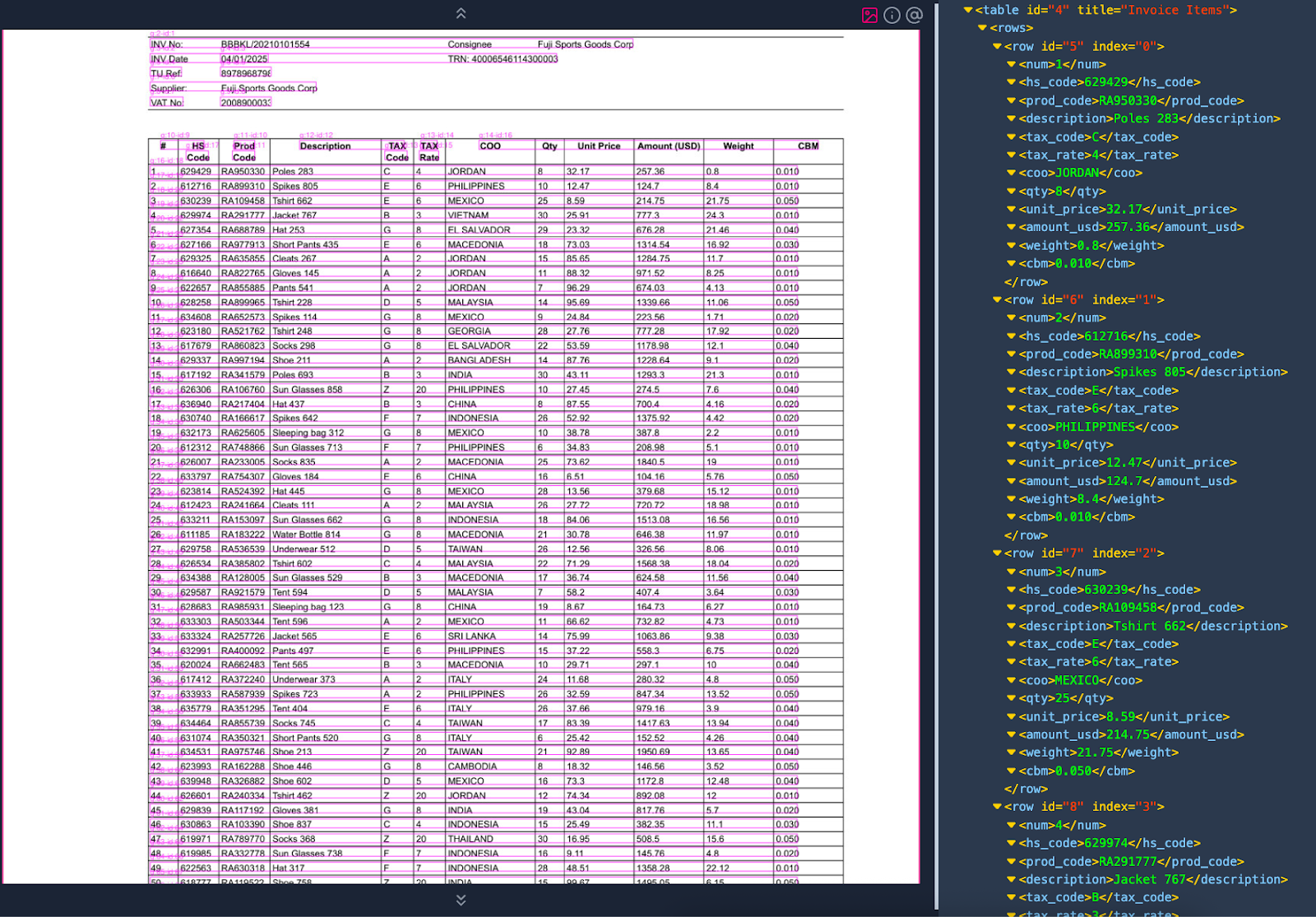
Invoice transformed into XML
As shown in the screenshot, Vertesia intelligently maps the table to an XML structure. One key aspect is that the transformation does not rewrite text using LLM. Thus the text in the XML file is 100% accurate when compared to the source.
Next we want to extract the line items in our own format that can be fed to our downstream applications using a consistent format.
This use case is natively supported by Vertesia and the execution is made as simple as an API call. The service will automatically identify the relevant tables in the document, and map the columns to the requested format, a CSV file for example. A complete code sample for this example can be found in our github repository.
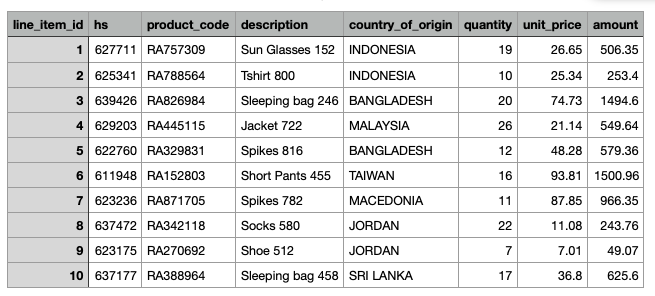
The first few line items mapped to the requested columns
You can start using Vertesia’s Semantic DocPrep by signing up for an account and learn more about it looking at the documentation.
Insights from Vertesia’s Eric Barroca on the GenAI Global Podcast, hosted by MIT Prof. John R. Williams and Dr. Abel Sanchez
Hashgraph leverages Vertesia’s generative AI platform to accelerate time to value and business impact across multiple departments.
Introducing Vertesia's Semantic DocPrep API service that eliminates LLM hallucinations and generates accurate, relevant results.