


# FINANCIAL HIGHLIGHTS
## Revenue
(EUR millions)

2022
2023
## Profit from recurring operations
(EUR millions)

2022
2023
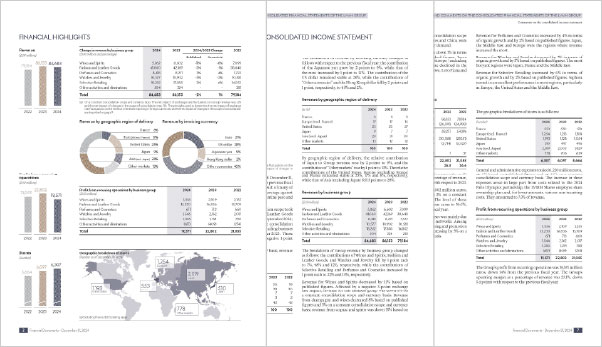
| Change in revenue by business group <br> (EUR millions and percentages) | 2024 | 2023 | 2024/2023 Change | | 2022 |
| :--: | :--: | :--: | :--: | :--: | :--: |
| | | | Published | Organic (a) | |
| Wines and Spirits | 5,862 | 6,602 | $-11 \%$ | $-8 \%$ | 7,099 |
| Fashion and Leather Goods | 41,060 | 42,169 | $-3 \%$ | $-1 \%$ | 38,648 |
| Perfumes and Cosmetics | 8,418 | 8,271 | $2 \%$ | $4 \%$ | 7,722 |
| Watches and Jewelry | 10,577 | 10,902 | $-3 \%$ | $-2 \%$ | 10,581 |
| Selective Retailing | 18,262 | 17,885 | $2 \%$ | $6 \%$ | 14,852 |
| Other activities and eliminations | 504 | 324 | - | - | 281 |
| Total | 84,683 | 86,153 | $-2 \%$ | 1\% | 79,184 |
(a) On a constant consolidation scope and currency basis. The net impact of exchange rate fluctuations on Group revenue was -2\% and the net impact of changes in the scope of consolidation was $-1 \%$. The principles used to determine the net impact of exchange rate fluctuations on the revenue of entities reporting in foreign currencies and
FINANCIAL HIGHLIGHTS
Revenue
Change in revenue by business group
2024
2023
2024/2023 Change
2022
(EUR millions)
(EUR millions and percentage)
Published
Organic
(a)
86,153 84,683
Wines and Spirits
5,862
6,602
-11%
-8%
7,099
79,184
Fashion and Leather Goods
41,060
42,169
-3%
-1%
38,648
Perfumes and Cosmetics
8,418
8,271
2%
4%
7,722
Watches and Jewelry
10,577
Intrinsic content referencing
Table normalization
Structured content extraction
Hierarchy preservation
Explicit tagging
Content filtering
Stateful reprocessing
Extensible Markup Language (XML) output
No hardware investment
No model management
Skip the complexity of running and tuning your own GenAI models
Automated failover
Intelligently switch between models for maximum reliability.
PDF Pages
Pricing is per page.
- 1—1,000 = FREE
- 1,001—1,000,000 = $0.001
- 1,000,001+ = $0.0008
Embedded images and tables are priced separately.
Images
Pricing is per page with one or more images
- 1—1,000 = FREE
- 1,001—1,000,000 = $0.002
- 1,000,001+ = $0.0016
Pricing example:
One page has two images: $0.001 + $0.002 = $0.003
Tables
Pricing is per page with one or more tables
- 1—1,000 = FREE
- 1,001—1,000,000 = $0.003
- 1,000,001+ = $0.0024
Pricing example:
One page has three tables: $0.001 + $0.003 = $0.004
Learn about the latest generative AI trends
Download DZone's latest GenAI trend report to learn why 70-95% of AI pilots never make it to production. Discover the architectural discipline, governance frameworks, and operational strategies that turn AI experiments into business value.
